Pivot tables
Pivot reports are very powerful tools for data analysis. They can be generated and used by any InstaDB user, but an administrator has option to write a pivot into database schema and share it to the users by embedding it in the menu.
Introduction
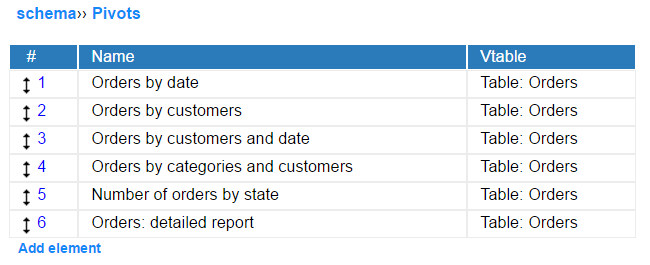
Pivots section of Schema Editor can contain any number of predefined pivot reports. The ready-made pivot tables do not limit the users ability to create own reports or temporary modify the existing ones. It means, that the predefined report can be easily modified or extended by a user. Of course that modification do not affect the scaffold written the schema.
Pivot reports follow the rules defined in row access control. It means that a user won't be able to see the records he/she don't have access and they will not be taken into account in the results of functions.
Note that links leading to the pivots are different in the standard menu section and in the "Administration" section (visible for admins only). In the first case a link leads to a ready pivot report. In the latter it leads to the pivot editor with all the values preset.
Pivot structure
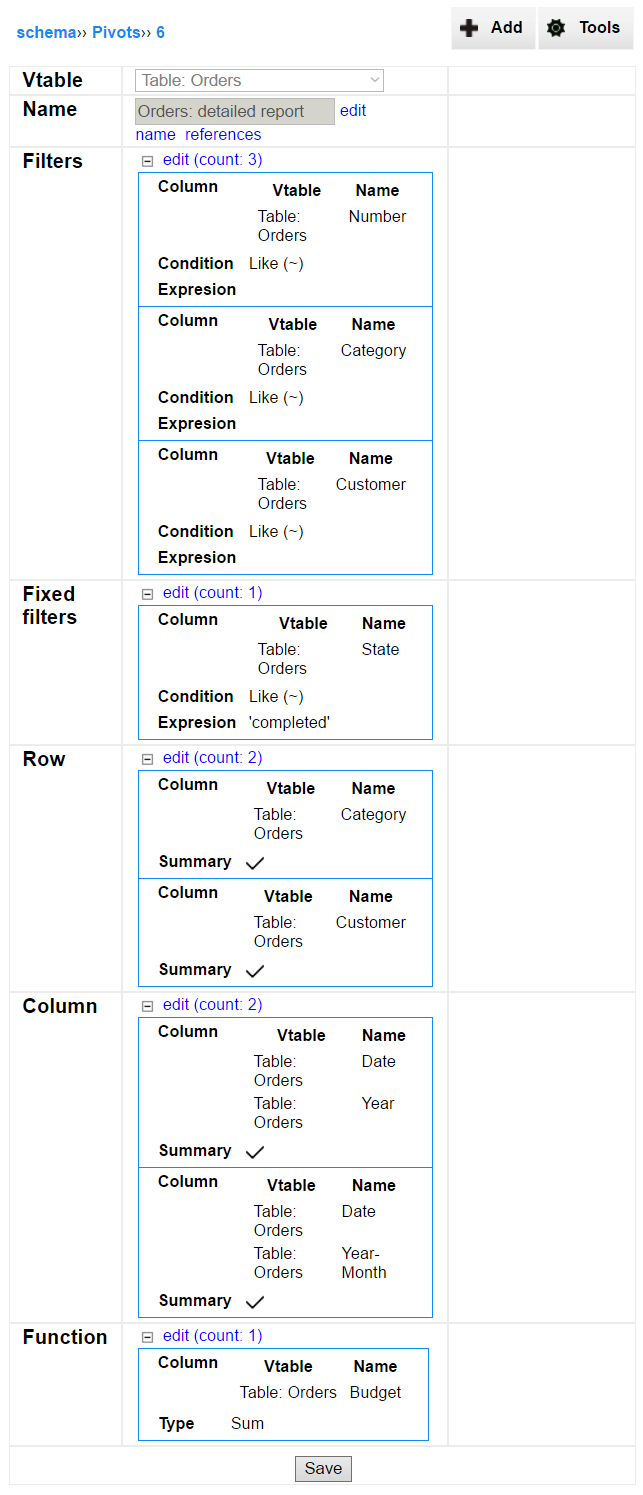
A pivot definition includes the following elements:
-
Vtable is a table or view, which records will be used for generating the report.
-
Name of the table, used in schema and displayed for users; must be unique.
-
Filters applied to the set of records before the functions results are calculated; they can be modified by user.
-
Fixed filters work as standard filters, but cannot be overwritten by a user.
-
Row section lets for selection column (or columns) to be used for grouping records along the vertical axis of pivot table.
-
Column section lets for selection row (or rows) to be used for grouping records along the horizontal axis of pivot table.
-
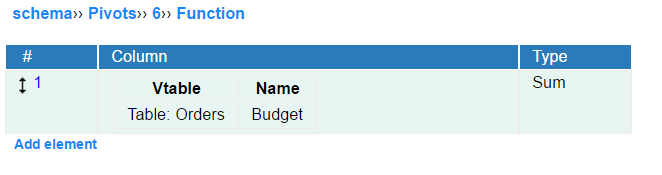
Function section is used for selecting function (or functions) for calculating the aggregation.
Pivot filters
These filters are similar to table filters, but lack the "Order" parameters, as the result is always an aggregation of records.
It is possible to add any number of filters to a pivot table. A user can always add new filters, modify existing the existing ones or even remove them. These modifications are stored neither in the database schema nor in the user session. It means that the default pivot settings are restored every time the user click the pivot item in the menu.
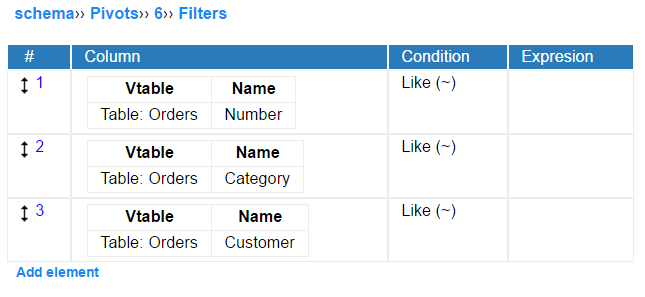
Pivot fixed filters
Just like table fixed filters, pivot fixed filters cannot be modified by a user.
Fixed filters limit user's access to data only at the level of interface. To fully prevent user access to some data the row access control mechanism must be used.
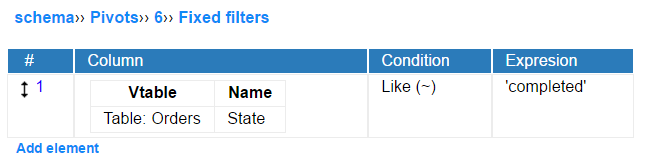
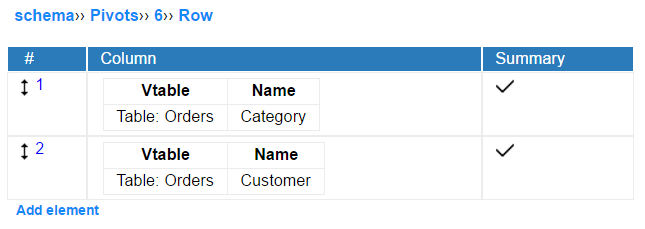
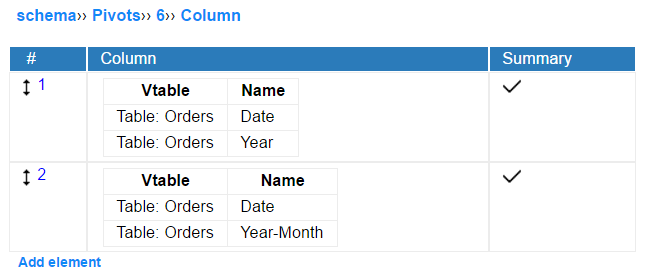
Pivot rows and columns
Pivot data can be grouped by one or more parameters. The pivot function(s) will take the data from every group separately and for any of them return a result.
If neither row nor column section is filled, the result will be a single value being a result of functions applied for all records fulfilling the criteria of filters and fixed filters.
In one-dimensional pivot table only a single row or single column is added. The result of aggregations will be then displayed in the last column or last row.
If one column and one row is selected, pivot table is two-dimensional. In such case the value in a (x,y) cell of the table is the result of application the function(s) to the set of records grouped by an x-column value and y-row value at the same time.
The pivot engine allow to create more than two-dimensional tables by adding multiple rows and columns to the pivot definition. In such case the grouping will be performed at every level of cell/row.
Rows and cells are defined by selecting a table column which value will be used for grouping. Optional "Summary" parameter lets to display the result of aggregation of all records in the group defined by the cell/row value. It is useful in two- and more dimensional tables.
Pivot functions
Pivot function is the only obligatory element of a pivot table definition. It is possible to specify one or more pivot functions. If more than one function is specified, each of cells in the table will contain multiple values, one for every function.
A function is applied or every cell of pivot table. In two- or more dimensional tables it is applied at every intersection of columns and rows.
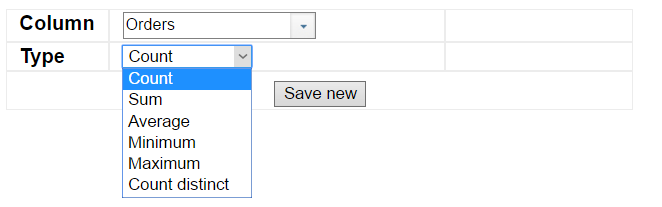
Currently the following set of functions can be used in InstaDB:
-
Count,
-
Count distinct,
-
Sum,
-
Average,
-
Minimum,
-
Maximum.